


Hướng dẫn tự học SQL và các nguồn luyện tập dành cho người mới bắt đầu

Mới bắt đầu làm quen với một ngôn ngữ mới, đặc biệt là ngôn ngữ code như SQL, chắc hẳn bạn sẽ cảm thấy khó khăn, ngợp với đống kiến thức cần phải học.
Bản thân mình lúc mới học SQL cũng vậy, giữa một “rừng” tài liệu về SQL mình luôn cảm thấy bối rối không biết bắt đầu học từ đâu, học thế nào là đủ, nguồn học nào dễ hiểu. Vì vậy mà sau thời gian học SQL từ đủ các nguồn, từ tài liệu, đến các khóa học miễn phí lẫn trả phí, mình đã tổng hợp thành một lộ trình học SQL cho người mới bắt đầu.
Nếu bạn mới đang làm quen với SQL thì đừng bỏ qua hướng dẫn tự học này nhé
Bạn nào chưa biết SQL là gì, có thể đọc thêm bài viết này: SQL là gì? Tất tần tật những gì bạn cần biết về SQL
Ai là người cần học SQL?
Kỹ năng sử dụng SQL để truy vấn (query) cũng ngày càng được nhiều người quan tâm, bao gồm cả những người không có nhiều kinh nghiệm về ngôn ngữ máy tính. Ví dụ, một số bộ phận Operations hoặc Fraud & Risks của các công ty sản phẩm “sống dựa” trên môi trường số như Fintech hoặc E-Commerce cũng được yêu cầu cần nắm được những kiến thức cơ bản về SQL để có thể tự truy vấn adhoc những dữ liệu sử dụng trong vận hành hàng ngày.
Điều đó có nghĩa là khả năng ứng dụng SQL là lớn và nhu cầu đối với các chuyên gia có kiến thức sâu rộng về SQL vẫn cao. Hiểu biết vững chắc về SQL có thể có giá trị cho nhiều vị trí khác nhau, bao gồm:
Database administration (DBA): Đây là công việc có trách nhiệm đảm bảo việc lưu trữ và quản lý dữ liệu của tổ chức chính xác, bao gồm các nhiệm vụ như quản lý nhiều cơ sở dữ liệu và cấu hình máy chủ cho nhiều mục đích sử dụng dữ liệu: sử dụng dữ liệu cho các quyết định kinh doanh, cho vận hành hàng ngày, cho một tính năng của sản phẩm,...
Data analysis và data science: Lĩnh vực này liên quan đến việc xử lý một khối lượng lớn dữ liệu và trích xuất thông tin chi tiết để hỗ trợ đưa ra quyết định kinh doanh và vận hành. Số liệu thống kê gần đây cho thấy rằng SQL vẫn phổ biến hơn đối với các chuyên gia dữ liệu hơn so với các ngôn ngữ khác như Python, R.
Database migration: Đây là chuyên ngành quản lý dữ liệu, với những công việc như di chuyển dữ liệu từ nhiều cơ sở dữ liệu khác nhau sang một cơ sở dữ liệu hoặc một máy chủ, tủ đĩa vật lý hoặc trên đám mây, chẳng hạn như Microsoft Azure.
Data architecture: Lĩnh vực này liên quan đến việc thiết kế cấu trúc hoặc xây dựng bộ quy tắc để quản lý khối lượng lớn dữ liệu từ nhiều nguồn khác nhau.

Cấu trúc của một hệ thống dữ liệu trong doanh nghiệp - Slide được trích từ khóa học SQL for Data Analysis
Web development: Lĩnh vực này yêu cầu kiến thức về xây dựng và quản lý cơ sở dữ liệu liên quan đến việc phát triển một trang web hoặc ứng dụng để vận hành. Tất cả các website đều có cơ sở dữ liệu backend lưu trữ dữ liệu về người dùng, thông tin về sản phẩm hiển thị trên trang web, thông tin về cách người dùng hoạt động trên website,...). Ví dụ, website thương mại điện tử Amazon sử dụng MySQL để quản lý dữ liệu. Vì vậy, các IT developer thường có kỹ năng về một số ngôn ngữ lập trình như C++, Java và SQL cũng là một bổ sung hữu ích cho danh sách này.
Bổ sung thêm kỹ năng SQL trong CV cũng sẽ là điểm sáng với các vị trí làm việc với dữ liệu như Data Analyst, Data Engineer hoặc Data Scientist, cũng như các vị trí trong các ngành liên quan phía trên.
Đọc thêm: Phân biệt các vị trí Data Analyst, Data Engineer hoặc Data Scientist
Tại sao Data Analyst cần phải biết SQL?
Chính bởi tầm quan trọng của dữ liệu, tầm quan trọng của SQL đối với các vị trí Analyst - những người làm việc với thông tin và dữ liệu càng lớn. SQL có nhiều khả năng:
Định nghĩa dữ liệu (Data definition): SQL được dùng để định nghĩa cấu trúc và tổ chức cách dữ liệu lưu trữ và mối quan hệ giữa những entity trong một cơ sở dữ liệu
Truy vấn dữ liệu (Data retrieval): SQL được dùng để truy xuất dữ liệu, nói cách khác lấy dữ liệu từ hệ thống quản lý cơ sở dữ liệu, ví dụ như cơ sở dữ liệu hướng đối tượng
Thay đổi dữ liệu (Data manipulation): SQL được dùng để bổ sung dữ liệu, loại bỏ dữ liệu hoặc thay đổi đè trên dữ liệu đã có trong cơ sở
Kiểm soát truy cập (Access control): SQL được dùng để hạn chế khả năng truy xuất, bổ sung và thay đổi dữ liệu, nhằm bảo vệ dữ liệu khỏi những truy nhập không chính đáng
Chia sẻ dữ liệu (Data sharing): SQL được dùng để điều phối việc chia sẻ dữ liệu của những người dùng đồng thời, đảm bảo rằng những thay đổi do một người dùng thực hiện không vô tình xóa sạch những thay đổi được thực hiện gần như cùng lúc bởi một người dùng khác
Cụ thể, SQL có thể:
Cho phép người dùng truy cập vào dữ liệu của cơ sở dữ liệu có cấu trúc để truy vấn thông tin
Cho phép người dùng mô tả dữ liệu (lấy được dữ liệu mô tả dữ liệu, kiểu dữ liệu,...)
Cho phép người dùng thay đổi, chỉnh sửa dữ liệu - đây là một phần rất quan trọng để trong quá trình xử lý, làm sạch và chuẩn bị dữ liệu cho những phân tích và khai phá dữ liệu trong quy trình phân tích của Data Analyst
Cho phép người dùng tích hợp với ngôn ngữ máy tính khác bằng cách sử dụng SQL modules, libraries và pre-compilers, ví dụ: có thể nhúng truy vấn SQL với ngôn ngữ lập trình Java để xây dựng tính năng phân tích CR hoặc tính năng tổng kết hiệu quả bán hàng,... trong một ứng dụng E-Commerce.
Cho phép người dùng kết hợp với các ngôn ngữ khác như Python, R để quản lý cơ sở dữ liệu, áp dụng xử lý, trực quan và khám phá dữ liệu - hữu ích cho việc phân tích và phát triển mô hình và thuật toán machine learning.
Cho phép người dùng tạo và xóa bảng khỏi cơ sở dữ liệu
Cho phép người dùng tạo bảng view (chỉ truy vấn mà không thay đổi được dữ liệu), đảm bảo tính an toàn và bảo mật nhờ dễ dàng phân quyền cho các nhóm người dùng khác nhau
Kết hợp với các công cụ BI (Business Intelligence) để xây dựng các dashboard, report để xử lý một khối lượng dữ liệu lớn một cách tự động mà không cần phụ thuộc vào các file Excel/ Google Sheets.
Ngay cả khi dữ liệu phi cấu trúc (audio, hình ảnh, video,...) và dữ liệu bán cấu trúc (XML, JSON,...) ngày càng nhiều, dữ liệu có cấu trúc và SQL là một phần quan trọng trong “hệ sinh thái” của dữ liệu.
Với những khả năng như trên, SQL là một phần rất quan trọng trong quy trình xử lý và phân tích dữ liệu của các Data Analyst, đặc biệt khi làm việc trong công ty có khối lượng dữ liệu lớn.
Đọc thêm: Lộ trình học Data Analysis cho dân trái ngành background Business
Lộ trình tự học SQL dành cho người mới bắt đầu

Nguồn ảnh: Arvind Dhakar
Tuần 1
Trong thời gian đầu, bạn sẽ làm quen với những khái niệm cơ bản và nền tảng nhất, ví dụ như cách để tạo ra cơ sở dữ liệu và câu lệnh SELECT.
Cơ sở dữ liệu là gì? Cấu trúc của một hệ quản trị cơ sở dữ liệu quan hệ (RDBMS) bao gồm những thành phần gì?
Sự khác biệt của Operational database và Analytical database
Tổng quan về các loại kiến trúc dữ liệu phổ biến như Data Warehouse, Data Lake,...
Giới thiệu về các loại cơ sở truy vấn: MySQL,PostgreSQL, Microsoft SQL Server, Oracle,... và các công cụ để truy vấn như DBeaver,...
Giới thiệu về các kiểu dữ liệu: string, datetime, integer, float, varchar, decimal, numeric, money, nvarchar, binary,....
Các câu lệnh định nghĩa dữ liệu (thay đổi cấu trúc của bảng):
CREATE: Tạo ra một bảng dữ liệu hoặc một bản view mới và xác định kiểu dữ liệu của các trường trong bảng. View trong SQL có thể được coi là một bảng dữ liệu ảo - tức là có các trường và các bản ghi như một bảng nhưng không được lưu trữ trong bộ nhớ như một bảng dữ liệu. Quản trị cơ sở dữ liệu có quyền tạo ra nhiều view khác nhau, các bản view sẽ giới hạn các trường cần xem, theo các điều kiện nhất định hoặc tùy chỉnh tên trường dữ liệu theo mục đích cá nhân. Các bảng dữ liệu có chứa các thông tin nhạy cảm (sensitive data - ví dụ như dữ liệu cá nhân) cũng thường được tạo ra nhiều bản view để hạn chế quyền truy cập và đảm bảo tính bảo mật của dữ liệu.
INSERT: Chèn bản ghi mới vào bảng dữ liệu đã có sẵn
ALTER :Thay đổi và điều chỉnh cấu trúc bảng dữ liệu đã có
DELETE: Xóa các bản ghi trong một bảng, có thể dùng cùng WHERE để xóa theo một điều kiện nhất định
DROP: Xóa toàn bộ một bảng hoặc một object khỏi cơ sở dữ liệu
TRUNCATE: Xóa toàn bộ bản ghi trong bảng, giải phóng bộ nhớ và không thể phục hồi lại
Trong đó, cần lưu ý một số định nghĩa các trường dữ liệu:
Primary Key (Khóa chính): Cột được xác định là giá trị thể hiện tính độc nhất của dòng dữ liệu đó trong bảng. Ví dụ: nếu khóa chính của bảng employee là mã nhân viên employee_id, thì sẽ chỉ có duy nhất một nhân viên được đánh mã là 5. Mỗi bảng chỉ có một khóa chính.
Foreign Key (Khóa ngoại): Đây là cột tham chiếu đến Khóa chính trong các bảng khác. Ví dụ: trong bảng transaction, có nhiều giao dịch được thực hiện bởi Nhân viên số 5. Sau đó, bạn có thể tạo Khóa chính trong bảng transaction, tham chiếu đến bảng employee. Điều này có nghĩa là bạn sẽ không thể thêm giao dịch của những nhân viên không có trong bảng Nhân viên.
NULL hoặc NOT NULL: NULL là trạng thái không có dữ liệu (khác với BLANK - là trống dữ liệu, hoặc dữ liệu có giá trị là một dấu cách). Nếu một cột được mặc định là NOT NULL, tất cả các dòng đều phải có giá trị ở cột đó, bất kể là dòng dữ liệu đã có hay khi update, bổ sung các dòng dữ liệu mới.
UNIQUE: Mặc định một trường dữ liệu sẽ chỉ chứa giá trị độc nhất không trùng lặp.
DEFAULT: Một giá trị mặc định, ví dụ GETDATE() để insert giá trị của ngày hiện tại khi truy vấn dữ liệu.
CHECK: Giới hạn giá trị dữ liệu có thể được insert cho một trường dữ liệu. Ví dụ, bạn có thể hạn chế các giá trị âm có thể được insert vào cột number_of_hours_worked.
Thay đổi bảng dữ liệu (thay đổi giá trị của bảng):
INSERT: Tạo ra một bản ghi mới trong bảng dữ liệu đã có, bằng cách sử dụng VALUES để bổ sung giá trị một cách chính xác, hoặc sử dụng SELECT để bổ sung dữ liệu từ những bảng khác.
DELETE: Xóa các bản ghi trong một bảng theo một điều kiện hoặc có thể xóa toàn bộ bảng. Khác với TRUNCATE và DROP, dữ liệu sau khi DELETE vẫn có thể khôi phục lại.
UPDATE: Thay đổi các bản ghi sẵn có trong một bảng dữ liệu. Khác với ALTER là Data Definition Language (DDL) còn UPDATE là Data Manipulation Language (DML); và ALTER sẽ thực hiện thay đổi ở cấp cấu trúc bảng dữ liệu, còn UPDATE sẽ thực hiện ở cấp giá trị dữ liệu
Cơ bản về một truy vấn:
SELECT: Lựa chọn các trường dữ liệu cần truy xuất hoặc thực hiện các tính toán
FROM: Xác định dữ liệu được truy xuất từ bảng nào, schema nào
WHERE: Giới hạn các dòng dữ liệu theo một điều kiện cụ thể để giới hạn số lượng bản ghi trả về.
Tuần 2
Các toán tử và chuyển đổi kiểu dữ liệu nâng cao:Bạn sẽ bắt đầu làm quen với những khái niệm nâng cao hơn như truy vấn con (subquery/nested query), Common Table Expression (CTEs) và các toán tử.
WITH: Thành thạo mệnh đề WITH để tạo ra các truy vấn phụ và có thể đặt tên để sử dụng nhiều lần trong một truy vấn. WITH có thể bẻ nhỏ các truy vấn SQL phức tạp thành nhiều truy vấn phụ để dễ dàng debug và tối ưu hiệu suất hơn.
CASE WHEN: Truy xuất hoặc gán nhãn dữ liệu theo một (hoặc nhiều) trường hợp.
EXISTS: Nó sẽ tạo thành truy vấn lồng nhau để lọc dữ liệu tồn tại trong truy vấn khác.
Toán tử số học: Sử dụng toán tử số học để lọc dữ liệu thuận tiện và chính xác, ví dụ như ‘=’, ‘>’, ‘<’, ‘<>’, ‘>=’,...
Toán tử đại diện:
‘~’: Trả về kết quả có chứa một giá trị đang tìm kiếm, ví dụ full_name ~ ‘Nguyen’ trả về các bản ghi có trường full_name có chứa từ ‘Nguyen’.
‘LIKE’, ‘iLIKE’ và ‘%’: Điều kiện full_name LIKE ‘%Nguyen%; cũng trả về kết quả tương tự ví dụ với toán tử ‘~’ phía trên.
AND & OR: AND trả về kết quả phải thỏa mãn đồng thời hai (hoặc nhiều) điều kiện, trong khi OR trả về kết quả thỏa mãn ít nhất một điều kiện.
BETWEEN & IN: Truy xuất điều kiện theo điều kiện trong một khoảng hoặc chính xác theo một giá trị.
NOT: Loại bỏ dữ liệu không phù hợp với một điều kiện, ví dụ NOT IN một số giá trị cụ thể.
Các hàm chuyển đổi kiểu dữ liệu ngày tháng: DATE_TRUNC(), DATEPART(), EXTRACT(), TO_DATE(), DATEDIFF(), DATE(), DATE_FORMAT(),...
Các hàm chuyển đổi theo kiểu dữ liệu số: ()::INT, ()::FLOAT,...
Các hàm chuyển đổi kiểu dữ liệu văn bản: ()::VARCHAR, TO_CHAR(), CONCAT(), LEFT(), RIGHT(), LTRIM(), TRIM(), LOWER(), UPPER(), REPLACE(), SUBSTR(),......
Các hàm chuyển đổi kiểu dữ liệu JSON: JSON_EXTRACT(), JSON_UNQUOTE(), JSON_EXTRACT_PATH_TEXT(), JSON_PARSE(),...
Các hàm xử lý và làm sạch dữ liệu: COALESCE(), NULLIF(),...
Đọc thêm: Data Cleaning là gì? Hướng dẫn các bước làm sạch dữ liệu
Tuần 3:
Thành thạo JOIN và UNION:
UNION: Mệnh đề UNION sẽ gộp các bản ghi của hai (hoặc nhiều) bảng có số lượng cột dữ liệu bằng nhau.
JOIN: Mệnh đề JOIN sẽ kết hợp các trường dữ liệu của hai (hoặc nhiều) bảng theo một điều kiện giao nhau.
INNER JOIN: Trả về các bản ghi có giá trị thỏa mãn điều kiện JOIN trong cả hai bảng
LEFT JOIN: Trả về tất cả các bản ghi từ bảng bên trái (table1) và mọi bản ghi phù hợp từ bảng bên phải (table2). Nếu không khớp, giá trị NULL sẽ được hiển thị cho các cột của bảng bên phải (table2)
RIGHT JOIN: Trả về tất cả các bản ghi từ bảng bên phải (table2) và mọi bản ghi phù hợp từ bảng bên trái (table1). Nếu không khớp, giá trị NULL sẽ được hiển thị cho các cột của bảng bên trái (table1)
FULL JOIN: Trả về tất cả bản ghi trong cả hai bảng dù có khớp điều kiện JOIN hay không.
CROSS JOIN: Trả về mọi tổ hợp các record từ cả hai bảng
SELF JOIN: Trả về các record có giá trị khớp với điều kiện khi một bảng được JOIN với chính nó
RECURSIVE JOIN: JOIN đệ quy cho phép query is a powerful feature that allows us to query hierarchical data which are used in relational databases. They are a compound operation that helps in accumulating records every time until a repetition makes no change to the result. Recursive queries are useful to build a hierarchy tree, best in working with hierarchical data such as org charts for the bill of materials traverse graphs or to generate arbitrary row sets. This involves joining a set with itself an arbitrary number of times. A recursive query is usually defined by the anchor part and the recursive part. Recursive joins are sometimes also called “fixed-point joins”. They are used to obtain the parent-child data. In SQL Recursive joins are implemented with recursive common table expressions. Recursive common table expression (CTEs) is a way to reference a query over and over again. Now we understand the Recursive Join in SQL by using an example.
ALIAS: Đổi tên trường hoặc đặt tên một bảng con, subquery khi truy xuất dữ liệu.
Đọc thêm: JOIN trong SQL là gì? JOIN và UNION có giống nhau?
Tuần 4:
Thành thạo các hàm tổng hợp, hàm tính toán và các hàm xử lý dữ liệu theo nhóm.
DISTINCT: Truy xuất các bản ghi duy nhất và loại bỏ các bản ghi trùng lặp.
Các hàm tổng hợp (Aggregate):
COUNT(): Hàm tính đếm số bản ghi theo điều kiện nhóm.
SUM(): Hàm tính tổng giá trị bản ghi theo điều kiện nhóm.
AVG(): Hàm tính giá trị trung bình của một trường dữ liệu theo điều kiện nhóm.
MIN(): Hàm trả về giá trị nhỏ nhất của một trường dữ liệu theo điều kiện nhóm.
MAX(): Hàm trả về giá trị nhỏ nhất của một trường dữ liệu theo điều kiện nhóm.
Các hàm tính toán MATHEMATICAL:
DIVIDE(): Hàm thực hiện phép chia giữa hai (hoặc nhiều) trường giá trị của một bản ghi.
MINUS(): Hàm thực hiện phép trừ giữa hai (hoặc nhiều) trường giá trị của một bản ghi.
GREATEST(): Trả về giá trị lớn nhất trong hai (hoặc nhiều) trường giá trị của một bản ghi.
LEAST(): Trả về giá trị thấp nhất trong hai (hoặc nhiều) trường giá trị của một bản ghi.
SQRT(): Trả về giá trị căn bậc hai.
SQUARE(): Trả về giá trị bình phương.
ROUND(): Trả về giá trị làm tròn một số thập phân sau dấu phẩy.
CEILING(): Trả về giá trị làm tròn lên theo số nguyên gần nhất.
FLOOR(): Trả về giá trị làm tròn xuống theo số nguyên gần nhất.
ORDER BY: Sắp xếp thứ tự của các dòng dữ liệu, theo chiều tăng dần/từ A tới Z (ASCENDING) hoặc giảm dần/từ Z tới A (DESCENDING)
GROUP BY: Nhóm dữ liệu theo một (hoặc nhiều) đối tượng để thực hiện hàm tổng hợp.
HAVING: Giới hạn điều kiện theo nhóm khi dùng kết hợp GROUP BY.
TOP & LIMIT: Giới hạn số lượng bản ghi trả về từ kết quả truy vấn.
WINDOW FUNCTIONS:
ROW_NUMBER(): Đánh số thứ tự liên tiếp bắt đầu từ 1 cho tất cả các hàng trong nhóm, theo thứ tự được sắp xếp bằng ORDER BY và không quan tâm đến những giá trị giống nhau (Ví dụ: 1,2,3,4,5,...)
RANK(): Xếp hạng các giá trị theo thứ tự tăng dần nhưng sẽ trả về thứ hạng giống nhau với các giá trị giống nhau và bỏ qua thứ hạng đó (Ví dụ: 1,1,3,4,5,...)
DENSE_RANK(): Xếp hạng các giá trị theo thứ tự tăng dần nhưng sẽ trả về thứ hạng giống nhau với các giá trị giống nhau và không bỏ qua thứ hạng đó và sẽ gán số liên tiếp giá trị cho hàng tiếp theo (Ví dụ: 1,1,2,3,4,...)
PERCENT_RANK: Xếp hạng các giá trị theo công thức (rank - 1)/ (row - 1). Trong đó: rank là thứ tự của giá trị đó (các giá trị giống nhau trả về thứ hạng giống nhau) và row là tổng số dòng (xét trong một partition). Tất cả các giá trị xếp hạng được chia tỷ lệ theo số dòng và nằm trong khoảng từ 0 đến 1. Ngoài ra, các dòng có giá trị đầu tiên luôn được gán giá trị xếp hạng là 0.
NTILE(): Xếp thứ tự cho các nhóm của bucket. Bucket là tập hợp của nhiều dòng liên tiếp và số lượng bucket được đặt làm tham số của hàm NTILE().
LAG(): Dịch chuyển giá trị xuống một dòng trong mỗi nhóm.
LEAD() trái ngược với hàm LAG(): Dịch chuyển giá trị lên một dòng trong mỗi nhóm.
FIRST_VALUE(): Gán giá trị đầu tiên trong nhóm, theo một số thứ tự xác định dòng nào sẽ là dòng đầu tiên.
LAST_VALUE() trái ngược với hàm FIRST_VALUE(): Gán giá trị cuối cùng trong nhóm, theo một số thứ tự xác định dòng nào sẽ là dòng đầu tiên.
NTH_VALUE(): Cho phép người dùng xác định giá trị nào trong đơn dòng sẽ được gán cho các dòng khác
Đọc thêm: Window Functions là gì? Tìm hiểu từ A-Z các hàm window functions trong SQL
Tuần 5:
Làm quen với các câu lệnh quản trị cơ sở dữ liệu và tối ưu truy vấn:
Làm việc với quyền truy cập dữ liệu: Quyền truy cập được tạo ra để DBA dễ dàng quản lý và bảo mật dữ liệu bằng cách cấp và thu hồi quyền truy cập cho người dùng. Một số quyền của hệ thống bao gồm quyền Connect (người dùng có thể tạo bảng, tạo view,...), quyền Resource (người dùng có thể sử dụng dung lượng và tài nguyên của hệ thống như insert dữ liệu, tạo trigger...) hoặc quyền DBA với mọi quyền sử dụng của hệ thống:
CREATE ROLE: Tạo quyền truy cập và các quyền hạn của quyền đó.
GRANT: Cấp quyền truy cập và thao tác với các bảng dữ liệu cho người dùng.
ALTER: Chuyển đổi quyền truy cập sang một người dùng khác.
REVOKE: Thu hồi quyền truy cập được cấp cho người dùng.
DROP: Xóa bỏ quyền truy cập.
Tối ưu truy vấn:
EXPLAIN: Khi thực hiện một truy vấn, bạn cần đảm bảo tính hiệu suất của truy vấn đó tới tài nguyên của hệ thống, đặc biệt nếu hệ thống có liên tiếp số lượng truy vấn lớn trong khoảng thời gian ngắn. Để kiểm tra hiệu suất của truy vấn, ví dụ như biết thứ tự thực hiện và mất bao nhiêu thời gian để chạy được kết quả của truy vấn đó, bạn có thể sử dụng mệnh đề EXPLAIN để hiểu được cách cơ sở dữ liệu thực hiện truy vấn đó, bao gồm nhật ký trình tối ưu hóa, cách join các bảng và thứ tự, thực hiện,... Nhờ vậy, bạn có thể biết được đâu là câu lệnh khiến truy vấn chưa đạt được hiệu suất tối ưu, từ đó bổ sung điều kiện giới hạn số lượng bản ghi cần chuyển đổi hoặc bổ sung truy vấn con để giảm tính phức tạp,...
Tổng hợp tài liệu và các khóa học SQL
Blog & website
Blog & website là những kênh để bạn có thể cập nhật những kiến thức, xu hướng mới một cách hiệu quả. Bên cạnh những trang blog cá nhân của những chuyên gia, những người có tầm ảnh hưởng trong lĩnh vực dữ liệu, các trang blog/website cung cấp các công cụ, giải pháp hoặc dịch vụ liên quan tới SQL cũng là một nguồn tài liệu giá trị mà bạn có thể tham khảo.
TM đã tổng hợp một số blog/website để bạn có thể tham khảo hoặc thực hiện các bài tập từ cơ bản tới nâng cao về kỹ năng SQL.
SQLZoo - Một trang web cung cấp cả hướng dẫn và bài tập thực hành cho những người mới bắt đầu với SQL.
PopSQL - Là một website có các bài tập tương tác để thực hiện các câu truy vấn dữ liệu. Website này cũng cho phép nhiều người dùng chia sẻ các câu truy vấn, lưu lại các truy vấn thường dùng,...
Learning SQL by Alan Beaulieu - Đây là một e-book miễn phí, cung cấp đầy đủ kiến thức về dữ liệu nói chung và SQL nói riêng.
Trang blog Data Analysis blog của Tomorrow Marketers - Với những bài viết chuyên môn được cập nhật liên tục, trang blog sẽ mang đến cho bạn nhiều kiến thức hữu ích về kỹ năng này.

Ngoài ra, để nắm được kiến thức cơ bản và tổng quan nhất về SQL, hãy lưu ngay cheat sheet tổng hợp các câu lệnh SQL phổ biến nhất để dễ dàng truy vấn, xử lý & tính toán data từ các cơ sở dữ liệu của công ty.
Khóa học ngắn hạn
Ngoài đọc tài liệu thì việc thường xuyên thực hành cũng là một phần quan trọng để bạn có thể ứng dụng lý thuyết và biến nó thành kỹ năng của mình. Ưu điểm của một khóa học ngắn hạn chính là kiến thức đã được tổng hợp và sắp xếp có lộ trình. Có rất nhiều khóa học e-learning bạn có thể tham gia, đây cũng là cơ hội bạn có thể thực hành và có một chứng chỉ để làm sáng CV:
TM Data School - SQL for Data Analysis

Bạn có thể tham khảo lộ trình học SQL với khóa học SQL for Data Analysis cung cấp trọn bộ kiến thức bài bản về hệ thống dữ liệu được cập nhật từ các chương trình Master of Science in Data Science hàng đầu thế giới:
Giai đoạn 1: Nắm vững kiến thức cơ bản về hệ thống dữ liệu:
Vai trò và cấu trúc của hệ thống dữ liệu, các loại hệ thống dữ liệu phổ biến, tiêu chuẩn cho một hệ thống dữ liệu tốt
Cách xây dựng một hệ thống dữ liệu bài bản: Data Collectors, Data Warehouse, Data pipeline
Kiến thức về Data Model: Hiểu về cấu trúc và các thành phần chính của Data Model bao gồm bảng, hàng, cột, khóa chính, khóa ngoại và các ràng buộc.
Giai đoạn 2: Học về SQL:
Cú pháp cơ bản của SQL: Tìm hiểu về cú pháp cơ bản của SQL bao gồm SELECT, INSERT, UPDATE, DELETE và các lệnh khác.
Truy vấn dữ liệu: Học cách truy vấn dữ liệu từ một hoặc nhiều bảng sử dụng các câu lệnh SELECT, JOIN, WHERE, GROUP BY, HAVING và ORDER BY.
Chỉnh sửa dữ liệu: Học cách thêm, cập nhật và xóa dữ liệu từ các bảng bằng cách sử dụng các lệnh INSERT, UPDATE và DELETE.
Quản lý cơ sở dữ liệu: Tìm hiểu về các lệnh CREATE, ALTER và DROP để quản lý cấu trúc của cơ sở dữ liệu và bảng.
Giai đoạn 3: Thực hành và ứng dụng:
Thực hành với cơ sở dữ liệu thực tế: Tìm hiểu và thực hành với một số cơ sở dữ liệu mã nguồn mở như MySQL, PostgreSQL hoặc SQLite.
Giải quyết các bài toán thực tế qua Capstone Project cuối khóa: Thực hành giải quyết các vấn đề thực tế bằng cách sử dụng SQL như tạo báo cáo, phân tích dữ liệu và trích xuất thông tin từ cơ sở dữ liệu.
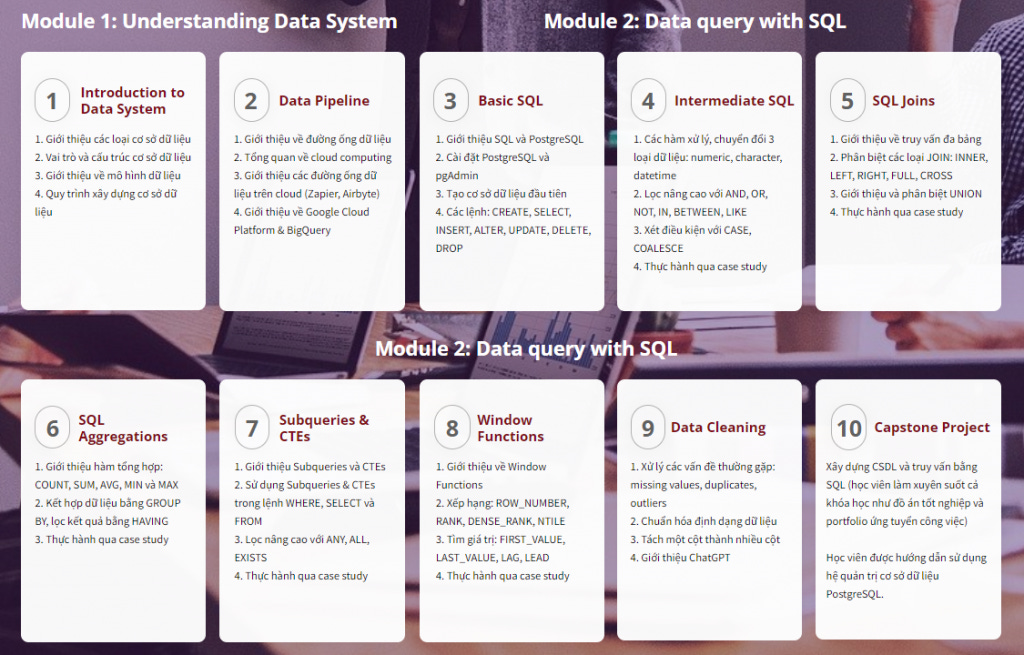
Nội dung SQL for Data Analysis tại TM Data School
Ngoài ra bạn có thể tham khảo một số khóa học ngắn của nước ngoài như:
SQLBolt - một khóa học tương tác miễn phí và giới thiệu những kiến thức cơ bản về SQL, bao gồm các mệnh đề cơ bản như SELECT, JOIN, WHERE, các hàm aggregate,...
SQL Tutorial at FreeCodeCamp - Khóa học SQL miễn phí của FreecodeCamp cung cấp kiến thức căn bản về SQL.
Datacamp - Một trang web cung cấp từ blog, cho tới các khóa học được chia theo nhiều cấp độ Beginner, Intermediate và Advanced, với đa dạng nội dung có sẵn và đa dạng bài tập thực hành.
Dataquest - Khóa học SQL Fundamental của Dataquest được xây dựng tập trung vào các kiến thức cơ bản và thực tiễn nhất, đảm bảo các kiến thức có thể phục vụ công việc.
Codecademy - Learn SQL của Codecademy là khóa học cho người mới bắt đầu với SQL. Khóa học sẽ hướng dẫn cách để sử dụng SQL và truy xuất dữ liệu từ cơ sở dữ liệu có cấu trúc. Với mỗi module, bạn sẽ được thực hành thao tác dữ liệu, viết truy vấn, sử dụng các hàm tổng hợp và giao tiếp với nhiều bảng.
W3Schools: Khóa học SQL Tutorial của website này sẽ cung cấp cho bạn đầy đủ mô tả, use case và được minh họa với nhiều hướng dẫn, ví dụ và bài tập khác nhau. Sau khi học bạn cũng có cơ hội được thực hành các bài tập trực tiếp trên website.
Coursera: Khóa học Introduction to Structured Query Language của nền tảng e-learning này sẽ hướng dẫn bạn từ việc tạo tạo ra một cơ sở dữ liệu MySQL. Bạn có thể nhận được một chứng chỉ sau khi kết thúc khóa học.
Udemy: Bạn cũng có thể mua một khóa học trên Udemy. Danh mục khóa học của nền tảng này cung cấp rất nhiều sự lựa chọn, tùy thuộc theo nhu cầu học, chương trình & nội dung. Ví dụ, với khóa học Complete SQL Bootcamp, bạn sẽ được học về cách sử dụng SQL để truy vấn dữ liệu, thực hiện các kỹ thuật phân tích,...
Tìm dataset để thực hành SQL ở đâu?
Học cần phải đi đôi với thực hành, sau khi đã học xong lý thuyết, để biến kiến thức trở thành kỹ năng của mình, bạn cần liên tục tìm kiếm cơ hội để tiếp xúc và thực hành SQL mỗi ngày. Vậy bạn có thể tìm được những bài toán và dataset để giải ở đâu? TM Data School đã tổng hợp một số trang web cung cấp dataset để bạn có thể tham khảo dưới đây:
Thực hành bài tập của các khóa học online đã được giới thiệu phía trên
Kaggle: Kaggle là cộng đồng online dành cho những ai đam mê cộng đồng Machine Learning (ML) và Khoa học dữ liệu. Với Kaggle, bạn có thể tìm kiếm các dataset có sẵn với kho 50.000 bộ dữ liệu. Bạn có thể sử dụng các bộ dữ liệu này để thực hành SQL, xa hơn là để train dữ liệu cho các mô hình dự báo. Kaggle cung cấp với nhiều định dạng khác nhau, từ CSV, JSON, SQLite,... ở nhiều lĩnh vực khác nhau, từ Retail, E-Commerce, Bank cho tới Healthcare,...

Google Trends: Google thu thập một khối lượng lớn dữ liệu của người dùng dưới cấp độ từng cú nhấp chuột, từng truy vấn tìm kiếm,... Mỗi báo cáo có thể tải xuống dưới dạng tệp CSV, sau đó nhập vào cơ sở dữ liệu của mình để thực hành.
IMDb: IMDb là một nền tảng đánh giá về phim, đạo diễn, diễn viên, biên kịch và tất tần tật về công nghiệp điện ảnh. IMDb hiện tại đang lưu trữ khối lượng dữ liệu lớn với 6 triệu bộ phim từ 30 năm trước. Trang web này cho phép bạn có thể truy cập và tải dữ liệu để sử dụng với mục đích cá nhân và không phải mục đích thương mại.
Airbnb: Tương tự, Airbnb cũng sở hữu dữ liệu về địa điểm của các nơi lưu trú, xếp hạng và giá thuê. Nền tảng này cho phép bạn có thể tải dữ liệu và sử dụng với mục đích cá nhân, không thương mại hóa.
Đọc thêm: 15 dataset để thực hành phân tích dữ liệu với Power BI
Tạm kết
Hy vọng lộ trình học SQL và những tài liệu ở trên sẽ giúp bạn có thể nhanh chóng làm quen và làm chủ SQL - một trong những “công cụ” cơ bản mà Data Engineer, Data Analyst/Business Analyst, Data Scientist đều cần biết có để làm việc hiệu quả với dữ liệu.
Nếu bạn vẫn cảm thấy mông lung, và cần có một “mentor” chỉ đường dẫn lối giúp bạn nhanh chóng trang bị những kiến thức về SQL, hãy tham khảo ngay khóa học SQL for Data Analysis của TM Data School.
