


Tìm hiểu về các loại hệ quản trị cơ sở dữ liệu quan hệ (RDBMS) và hướng dẫn cài đặt PostgreSQL cho thực hành truy vấn SQL


TM Data School - Trước cơ sở dữ liệu quan hệ, các doanh nghiệp sử dụng hệ thống cơ sở dữ liệu phân cấp, tương ứng các thư mục sao lưu trên máy tính. Tuy nhiên, cách lưu trữ dữ liệu này gặp phải hạn chế lớn trong việc thiếu tính linh hoạt khi khám phá dữ liệu, phức tạp và yêu cầu lớn về phần cứng để lưu trữ khi dữ liệu ngày càng nở ra.
Hệ quản trị cơ sở dữ liệu (DBMS) là giải pháp cho những vấn đề này, nhờ tách việc lưu trữ dữ liệu vật lý khỏi việc quản lý và sử dụng cơ sở dữ liệu.
Trong bài viết này, hãy cùng TM Data School tìm hiểu về hệ quản trị cơ sở dữ liệu của dữ liệu quan hệ (RDBMS) là gì và các RDBMS phổ biến nhất hiện nay nhé!
1. Cơ sở dữ liệu quan hệ là gì? Cấu thành của cơ sở dữ liệu quan hệ?
Cơ sở dữ liệu quan hệ là gì?
Giả sử, một doanh nghiệp có hai bảng dữ liệu lưu trữ về thông tin đơn hàng được xử lý: bảng thứ nhất là customer để lưu trữ thông tin của khách hàng, với các trường dữ liệu như tên, địa chỉ, số điện thoại và thông tin liên hệ khác, và bảng còn lại order lưu trữ thông tin về đơn hàng của mỗi khách hàng, mỗi bản ghi bao gồm ID của khách hàng đã đặt hàng, sản phẩm đặt hàng, số lượng, kích thước và màu sắc đã chọn, ngày tạo đơn hàng, ngày đơn hàng được giao hàng thành công, tình trạng đơn hàng,...
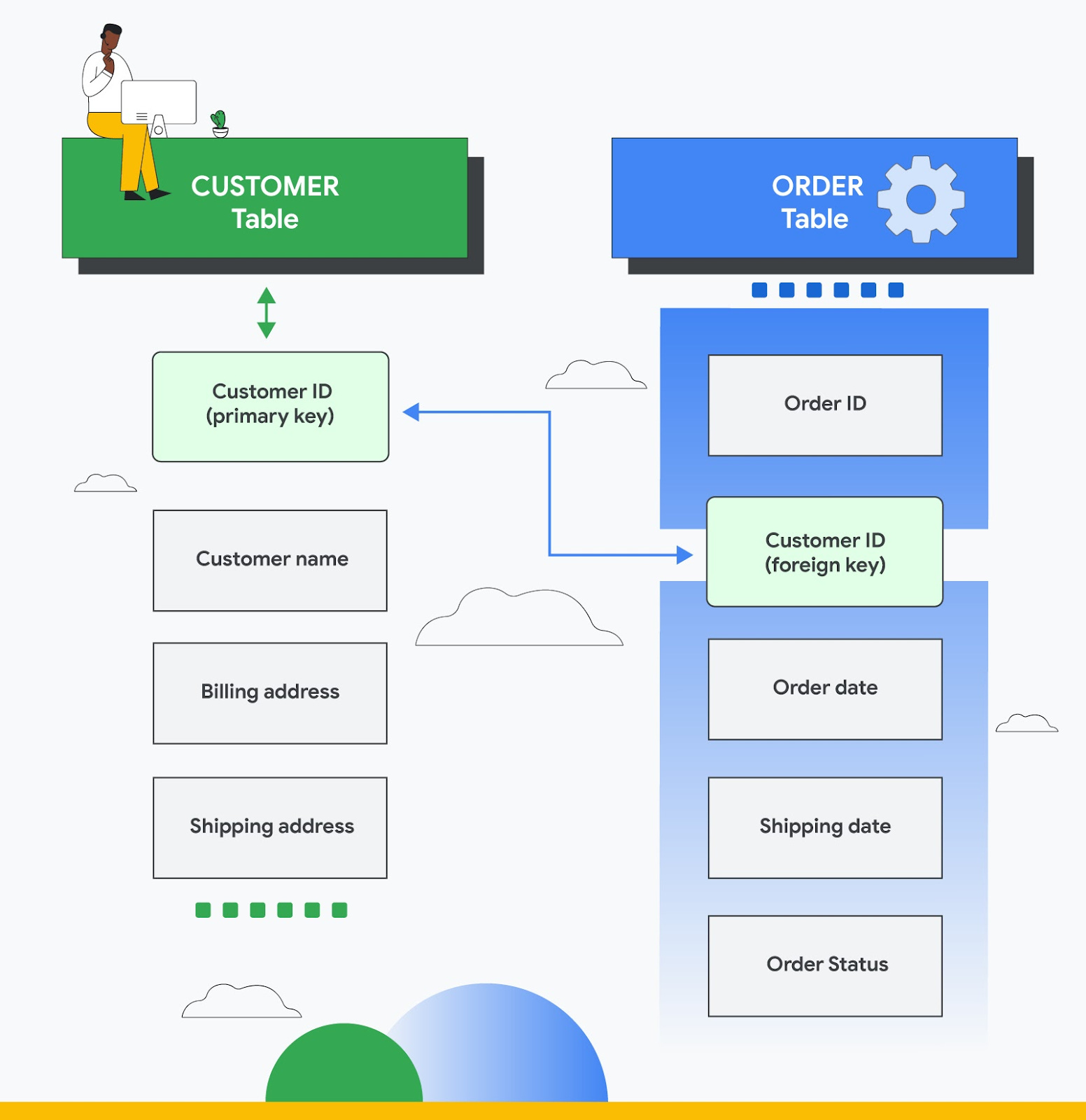
Trong bảng customer, customer_id là khóa định danh duy nhất khách hàng là ai trong cơ sở dữ liệu quan hệ. Không có khách hàng nào khác có cùng ID. Trong bảng order, order_id thì là khóa chính (primary key) để định danh một đơn hàng cụ thể.
Hai bảng này có thể kết nối thông qua hai cột giá trị chung: id trong bảng customer và customer_id trong bảng order - dựa vào đây, có thể tạo ra mối quan hệ giữa hai bảng. Khi truy vấn dữ liệu, có thể bổ sung các trường dữ liệu khách hàng tương ứng của mỗi đơn hàng.
Như vậy, cơ sở dữ liệu quan hệ là cấu trúc các bảng đối tượng (các bảng dữ liệu, view, chỉ mục) có mối quan hệ với nhau.
Mối quan hệ này tách biệt với cấu trúc lưu trữ vật lý. Database administrators sẽ quản lý việc lưu trữ dữ liệu vật lý mà không ảnh hưởng đến quyền truy cập vào dữ liệu đó dưới dạng cấu trúc logic. Ví dụ: đổi tên tệp cơ sở dữ liệu sẽ không đổi tên các bảng được lưu trữ trong đó.
Đặc điểm của cơ sở dữ liệu quan hệ
Entity Integrity: Các bản ghi trong cùng một bảng không được trùng lặp hoàn toàn. Để đảm bảo điều này và đảm bảo tính hợp lệ của dữ liệu khi xảy ra lỗi giao dịch hoặc các rủi ro khác, RDBMS đã có cơ chế ACID:
Atomicity (Tính nguyên tử) yêu cầu toàn bộ giao dịch phải được thực hiện thành công. Nếu một phần của giao dịch không thành công thì mọi thay đổi được thực hiện như một phần của giao dịch sẽ được khôi phục.
Consistency (Tính nhất quán) yêu cầu dữ liệu được ghi vào cơ sở dữ liệu quan hệ phải tuân thủ tất cả các quy tắc và hạn chế đã xác định, bao gồm các ràng buộc (constraints), phân tầng (cascades) và trình kích hoạt (triggers).
Isolation (Tính cô lập) yêu cầu mỗi giao dịch phải độc lập với chính nó. Khi nhiều người dùng cố gắng sửa đổi dữ liệu trong cơ sở dữ liệu quan hệ cùng một lúc, các cơ chế kiểm soát đồng thời sẽ ngăn họ ghi đè lên các thay đổi của nhau.
Durability (Tính bền vững) yêu cầu tất cả các thay đổi được thực hiện đối với cơ sở dữ liệu quan hệ là vĩnh viễn sau khi giao dịch được hoàn thành thành công.
Referential Integrity: Chỉ những bản ghi của một bảng không được sử dụng bởi những bảng khác mới có thể bị xóa. Nếu không, nó có thể dẫn đến sự không nhất quán dữ liệu.
User-defined Integrity: Các quy tắc do người dùng xác định dựa trên tính bảo mật và quyền truy cập. Cơ sở dữ liệu quan hệ cung cấp quyền truy cập cho nhiều người dùng cùng với các đặc quyền cho phép quản trị viên cơ sở dữ liệu có toàn quyền kiểm soát các hoạt động trong cơ sở dữ liệu và cấp các cấp độ truy cập khác nhau cho những người dùng khác.
Domain integrity: Các cột của bảng cơ sở dữ liệu được đặt trong một số giới hạn có cấu trúc, dựa trên các giá trị mặc định, loại dữ liệu hoặc phạm vi.
Normalization: Để giảm thiểu dư thừa dữ liệu, hạn chế dữ liệu trùng lặp, từ đó giảm kích thước dữ liệu trên đĩa và giảm chi phí lưu trữ, cơ sở dữ liệu quan hệ tuân theo các quy tắc toàn vẹn nhất định (Normalization, với các cấp độ 1NF, 2NF, 3NF và BCNF). Ví dụ: một quy tắc toàn vẹn có thể chỉ định rằng các hàng trùng lặp không được phép trong một bảng để loại bỏ khả năng thông tin sai sót khi đưa vào cơ sở dữ liệu.
Một số thành phần chính của một cơ sở dữ liệu quan hệ
Data model
Dữ liệu trong cơ sở dữ liệu quan hệ được lưu trữ ở định dạng bảng có cấu trúc, đồng thời, mối quan hệ linh hoạt giữa các bảng và cho phép sử dụng SQL để viết các truy vấn có độ phức tạp khác nhau cũng mang lại tính linh hoạt cho việc quản lý dữ liệu.

Các thành phần của Data Model - Slide khóa học Data System with SQL
Cơ sở dữ liệu quan hệ được tạo thành từ các bảng biểu diễn các đối tượng hoặc khái niệm trong thế giới thực thường được gọi là các thực thể (entities).
Mỗi cột trong bảng chứa một loại dữ liệu nhất định được gọi là thuộc tính (attributes) và một trường (fields) lưu trữ giá trị thực của thuộc tính.
Dữ liệu phải được lưu trữ dưới dạng bảng và được sắp xếp dưới dạng hàng và cột. Các hàng (rows) và cột (columns) trong bảng biểu thị một tập hợp các giá trị liên quan của một đối tượng hoặc thực thể.
Tập hợp các bản ghi như vậy được gọi là số lượng bản số (cardinality) của bảng.
Mỗi bản ghi trong bảng được định danh bằng một mã duy nhất được gọi là khóa chính (primary key). Khóa ngoại (foreign key) tham chiếu khóa chính của bảng hiện có khác và tạo kết nối logic. Các hàng giữa nhiều bảng liên kết với nhau bằng cách sử dụng cặp khóa chính/khóa ngoại. Ví dụ: mỗi hàng của bảng đơn hàng có thể chứa một khóa ngoại chứa ID khách hàng, khóa này xác định hàng trong bảng khách hàng chứa tất cả thông tin về khách hàng.
Đọc thêm: Data Modeling là gì? Cách xây dựng Data Model trong Power BI
SQL
Ngôn ngữ truy vấn có cấu trúc (SQL) là phương thức chính để giao tiếp với cơ sở dữ liệu quan hệ. Tất cả các công cụ cơ sở dữ liệu quan hệ phổ biến đều hỗ trợ ANSI SQL tiêu chuẩn. SQL có thể được sử dụng để bổ sung, cập nhật, xóa hoặc truy xuất dữ liệu từ một cơ sở dữ liệu.
Transactions
Giao dịch của một cơ sở dữ liệu quan hệ là một hoặc nhiều câu lệnh SQL chạy dưới dạng một chuỗi các thao tác và tạo thành một đơn vị công việc logic duy nhất. Trong khái niệm cơ sở dữ liệu quan hệ, một giao dịch sẽ dẫn đến COMMIT hoặc ROLLBACK. Hệ thống quản lý cơ sở dữ liệu xử lý mọi giao dịch một cách mạch lạc và đáng tin cậy, độc lập và tách biệt với các giao dịch khác.
Stored procedures
Truy cập dữ liệu bao gồm nhiều hành động lặp đi lặp lại. Ví dụ: một truy vấn đơn giản để lấy thông tin từ bảng dữ liệu có thể cần được lặp lại hàng trăm hoặc hàng nghìn lần để tạo ra kết quả mong muốn. Cơ sở dữ liệu quan hệ cho phép các thủ tục được lưu trữ (stored procedures), là các khối mã có thể được truy cập bằng một lệnh gọi ứng dụng đơn giản. Ví dụ: một thủ tục lưu trữ duy nhất có thể cung cấp việc gắn thẻ bản ghi nhất quán cho người dùng nhiều ứng dụng. Các thủ tục lưu trữ cũng có thể giúp nhà phát triển đảm bảo rằng một số chức năng dữ liệu nhất định trong ứng dụng được triển khai theo một cách cụ thể.
Database locking và concurrency
Trong các cơ sở dữ liệu chỉ có một người dùng, người dùng có thể sửa đổi dữ liệu trong cơ sở dữ liệu mà không cần lo lắng tới khả năng có người dùng khác cùng sửa đổi dữ liệu cùng một lúc. Tuy nhiên, với những cơ sở dữ liệu có nhiều người, đến việc những người dùng khác sửa đổi cùng một dữ liệu cùng lúc. Tuy nhiên, trong cơ sở dữ liệu nhiều người dùng, mâu thuẫn có thể phát sinh khi nhiều người dùng hoặc ứng dụng read và write dữ liệu tại cùng một thời điểm. Do đó, cơ chế kiểm soát tính đồng thời của dữ liệu (data concurrency) và tính nhất quán (data consistency) của dữ liệu cũng là một phần của RDBMS có nhiều người dùng.
Khóa (locking) và kiểm soát đồng thời (simultaneous control - MVCC) là hai kỹ thuật được các RDBMS sử dụng để giải quyết bài toán này:
Cơ chế Locking ngăn người dùng và ứng dụng khác truy cập dữ liệu trong khi dữ liệu đang được cập nhật. Ví dụ, với Oracle, áp dụng locking ở cấp bản ghi, để lại các bản ghi khác trong bảng.
Cơ chế Kiểm soát đồng thời đa phiên bản (MVCC) sẽ duy trì các phiên bản bản ghi riêng biệt, cho phép người đọc truy cập vào các bản snapshot của cơ sở dữ liệu nhất quán mà không bị chặn bởi các hoạt động write đang diễn ra. MVCC đảm bảo tính nhất quán của cơ sở dữ liệu bằng cách cho phép các giao dịch chỉ truy cập vào các phiên bản bản ghi hợp lệ đó tại thời điểm giao dịch mà không ảnh hưởng đến chế độ read của các giao dịch đồng thời khác. Nói cách khác, MVCC kiểm soát khả năng read những dữ liệu không mâu thuẫn với dữ liệu được write, vì vậy write dữ liệu mới sẽ không chặn được câu lệnh read và ngược lại.
Ngoài ra, cơ sở dữ liệu còn bao gồm nhiều đối tượng khác, ví dụ:
Database Schema (Lược đồ cơ sở dữ liệu): Định nghĩa cấu trúc của một cơ sở dữ liệu, bao gồm các bảng, cột, kiểu dữ liệu, ràng buộc dữ liệu (constraints), và mối quan hệ (relationship) giữa các bảng.
Constraints (Ràng buộc): Bao gồm các quy tắc để bảo đảm tính toàn vẹn của dữ liệu như ràng buộc khóa chính (primary key), khóa ngoại (foreign key), ràng buộc duy nhất (unique), và các điều kiện kiểm tra (check conditions).
Indexes (Chỉ mục): Các cấu trúc dữ liệu giúp tăng tốc độ truy xuất dữ liệu từ cơ sở dữ liệu.
Views (Chế độ xem): Cấu trúc ảo cho phép truy cập vào dữ liệu của một hoặc nhiều bảng dưới dạng một bảng ảo.
2. Hệ cơ sở dữ liệu quan hệ (Relational Database Management System - RDBMS) là gì?
Hệ cơ sở dữ liệu quan hệ (Relational Database Management System - RDBMS) là phần mềm được thiết kế để lưu trữ, quản lý các đối tượng và truy xuất dữ liệu của một cơ sở dữ liệu quan hệ. Hệ thống cung cấp một bộ công cụ toàn diện để quản lý cơ sở dữ liệu, đảm bảo tính bảo mật, nhất quán và toàn vẹn dữ liệu.
RDBMS sẽ phù hợp với những doanh nghiệp:
Có dữ liệu đã được cấu trúc hóa, và cấu trúc không thay đổi quá thường xuyên
Hệ thống dữ liệu dựa trên giao dịch (transaction-based)
Tính toàn vẹn và bảo mật dữ liệu là ưu tiên của doanh nghiệp
Yêu cầu tính linh hoạt khi thao tác với dữ liệu
Không cần mở rộng quy mô cơ sở dữ liệu quá nhanh
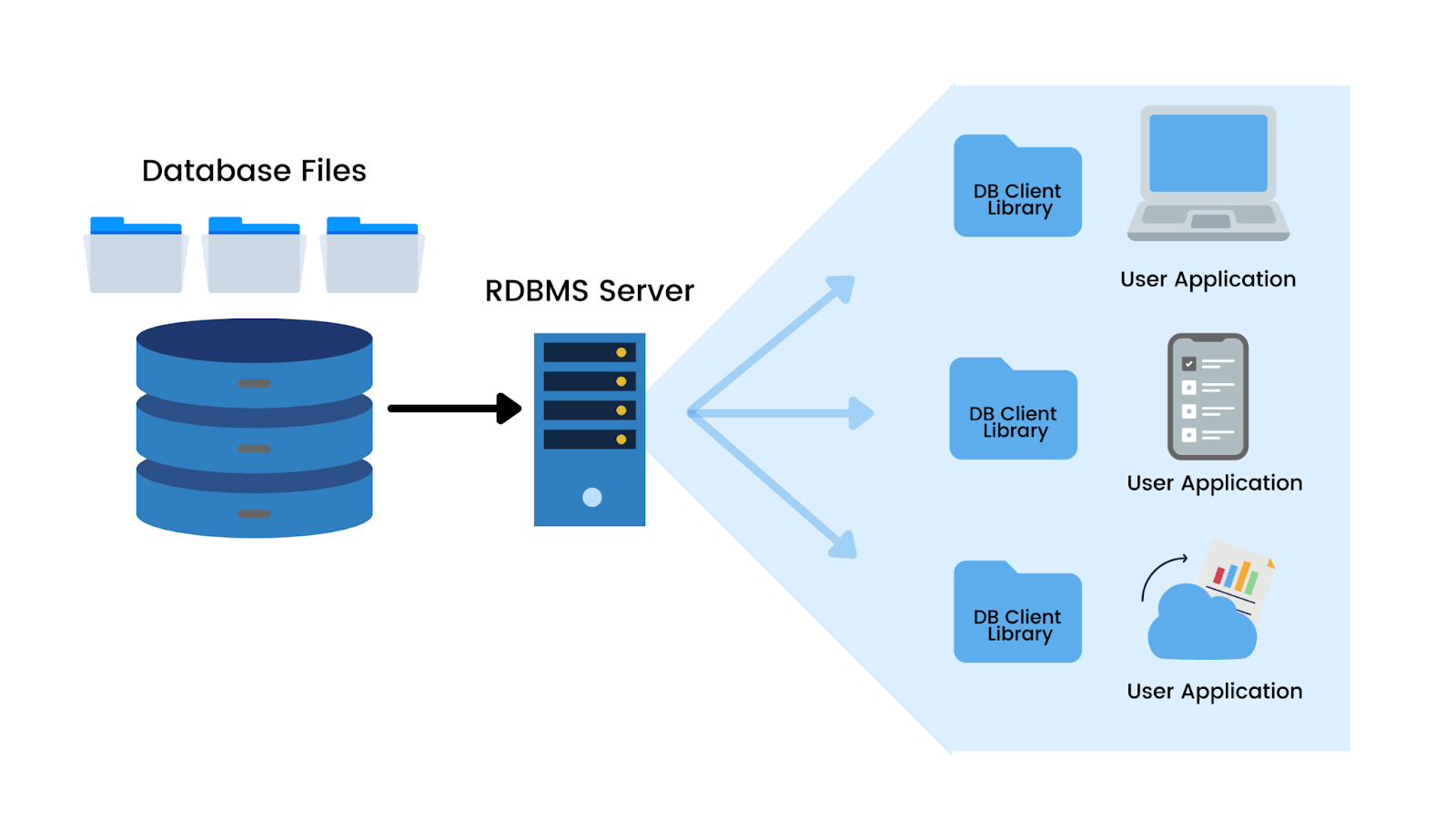
Nguồn ảnh: Nextnet Solutions
3. Các Hệ Quản Trị Cơ Sở Dữ Liệu (DBMS) phổ biến
Oracle Database (PLSQL)
Oracle DB là cơ sở dữ liệu có cấu trúc nguồn đóng được thương mại hóa của tập đoàn Oracle và hỗ trợ các hệ điều hành macOS, Windows và Linux.
Oracle là hệ quản trị cơ sở dữ liệu nổi tiếng, lâu đời với khả năng lưu trữ dữ liệu và khả năng mở rộng, với một loạt các công cụ phân tích và lưu trữ dữ liệu, chẳng hạn khả năng nén nâng cao, chế độ xem cụ thể và phân vùng. Dù vậy, với mức chi phí cao bao gồm chi phí cho phần cứng và chi phí cấp phép, Oracle chủ yếu được sử dụng bởi các doanh nghiệp lớn với mô hình kinh doanh phức tạp và phát sinh khối lượng dữ liệu lớn hàng ngày, tại Việt Nam chủ yếu là các ngân hàng.
Điểm cộng:
Là sản phẩm của ông lớn đi đầu trong ngành dữ liệu, vì vậy Oracle luôn nghiên cứu để cung cấp các tính năng và cải tiến mới nhất.
Hiệu suất mạnh, có nhiều tính năng nâng cao như Real Application Clusters (RAC) về khả năng chịu lỗi: sao lưu, vá lỗi, giám sát và khả năng mở rộng nhờ có thể thay đổi quy mô phần cứng.
Có bộ công cụ toàn diện và khả năng áp dụng rộng rãi trong ngành.
Khả năng tích hợp sâu với nền tảng đám mây, tạo điều kiện thuận lợi cho các kiến trúc hybrid và cloud-native.
Các tính năng bảo mật như mã hóa nâng cao (encryption) và che giấu dữ liệu (data masking).
Điểm trừ:
Không có phiên bản miễn phí, không có open source và chi phí quá cao đối với các doanh nghiệp nhỏ.
Yêu cầu cập nhật phần cứng thường xuyên.
Learning curve dốc
Quá trình cài đặt ban đầu rất phức tạp.
Việc chuyển đổi từ các hệ thống khác sang Oracle có thể tiêu tốn nhiều tài nguyên và cơ cấu hỗ trợ của doanh nghiệp.
Microsoft SQL Server (T-SQL)
Microsoft SQL Server là sản phẩm thuộc quyền sở hữu của Microsoft, với điểm cộng lớn nhất là khả năng tích hợp liền mạch với các sản phẩm khác của hệ sinh thái Microsoft.
SQL Server hỗ trợ các hệ điều hành Windows và Linux, có khả năng tạo điều kiện truy cập thông qua các truy vấn SQL và giao diện đồ họa người dùng.
SQL Server được biết đến với độ tin cậy, khả năng mở rộng và dễ sử dụng. Nó cũng cung cấp một loạt tính năng để lưu trữ và phân tích dữ liệu, bao gồm các chỉ mục của kho lưu trữ cột, OLTP trong bộ nhớ và polybase.
Các ứng dụng doanh nghiệp lớn thường sử dụng cơ sở dữ liệu Microsoft SQL Server và tận dụng nhiều tính năng với phiên bản SQL Server hiện tại, bao gồm tính toàn vẹn tham chiếu (referential integrity), kiểm soát đồng thời nhiều phiên bản (multi-version concurrency control), tính sẵn có của dữ liệu (higher availability), khả năng khóa chi tiết (fine-grained locking) và độ ổn định cao hơn (greater stability).
Điểm cộng:
Độc lập và có hiệu suất xử lý dữ liệu lớn
Có khả năng tiết kiệm tài nguyên vì nó có thể thích ứng với các tài nguyên
Có khả năng truy cập từ các thiết bị di động như smartphone
Có thể hoạt động với mọi sản phẩm của Microsoft: Hệ thống cơ sở dữ liệu này sử dụng Dịch vụ phân tích máy chủ SQL (SSAS) để phân tích dữ liệu, Dịch vụ báo cáo máy chủ SQL (SQL Server Reporting Services - SSRS) để tạo báo cáo và Dịch vụ tích hợp máy chủ SQL (SQL Server Integration Services - SSIS) để thực hiện các hoạt động ETL.
Dễ dàng thiết lập, vận hành và mở rộng quy mô mà vẫn đảm bảo phục hồi dữ liệu liền mạch nhờ khả năng tích hợp đám mây với Azure. Bạn có thể triển khai nhiều phiên bản SQL Server, bao gồm Express, Web, Standard và Enterprise. Vì Amazon RDS for SQL Server cung cấp cho bạn quyền truy cập trực tiếp vào các khả năng gốc của SQL Server nên các ứng dụng và công cụ của bạn sẽ hoạt động mà không có bất kỳ thay đổi nào.
Điểm trừ:
Chi phí cao
Nhập và xuất các tệp dữ liệu không tương thích.
Hệ thống yêu cầu điều chỉnh và tối ưu hóa định kỳ để xử lý các tập dữ liệu rất lớn một cách hiệu quả.
MySQL
MySQL là máy chủ cơ sở dữ liệu SQL mã nguồn mở, phổ biến và dễ sử dụng nhất được sử dụng rộng rãi để phát triển ứng dụng web. Bên cạnh phiên bản nguồn mở được thiết kế để hỗ trợ các câu lệnh SQL cơ bản, phiên bản thương mại dành cho doanh nghiệp cũng cung cấp một loạt tiện ích mở rộng và plugin bổ sung.
Cơ sở dữ liệu được viết bằng C và C++ và hỗ trợ nhiều nền tảng khác nhau như Hệ điều hành Windows Server và các bản phân phối Linux như RHEL 7 và Ubuntu. MySQL cũng tuân thủ hệ thống ACID để đảm bảo tính nhất quán trong giao dịch và cung cấp nhiều Connectors và API khác nhau như C, C++, Java, PHP,...
Điểm cộng:
Là mã nguồn mở, MySQL có lợi thế về chi phí, đặc biệt cho các công ty khởi nghiệp và doanh nghiệp vừa và nhỏ. Kiến trúc module của MySQL cho phép cấu hình có thể tùy chỉnh, phục vụ các nhu cầu hiệu suất đa dạng.
MySQL cung cấp kết nối liên tục, phù hợp với các doanh nghiệp cần lưu trữ dữ liệu OLTP và các ứng dụng web và các dự án khác có tần suất phát sinh giao dịch lớn.
Hệ thống cơ sở dữ liệu MySQL có tốc độ xử lý câu lệnh nhanh nhờ sử dụng kiến trúc máy chủ/máy khách (server/client architecture) bao gồm máy chủ SQL đa luồng (multi-threaded SQL server). Bản chất đa luồng này của MySQL cho phép đạt hiệu suất cao hơn vì các luồng nhân (kernel threads) có thể tận dụng số lượng CPU lớn.
MySQL có lợi thế hơn PostgreSQL về các hoạt động cần đọc nhiều (read-heavy operations).
Đơn giản để cài đặt và có cộng đồng rộng người dùng lớn.
Có khả năng thích ứng và sao lưu nhờ tính năng sao chép từ master sang slave và từ master sang master. Tính năng này hỗ trợ mở rộng quy mô số lần đọc và các tình huống chuyển đổi dự phòng trong trường hợp ngừng hoạt động. Đặc biệt, phiên bản MySQL Enterprise có các tính năng bổ sung như Mã hóa dữ liệu (Transparent Data Encryption - TDE), Sao lưu doanh nghiệp MySQL (MySQL Enterprise Backup) và lưu trữ tài liệu MySQL (MySQL document store).
Khả năng bảo mật với Access Privilege System (Hệ thống đặc quyền truy cập MySQL) cung cấp tính năng xác thực người dùng, hệ thống quản lý tài khoản người dùng và các kết nối được mã hóa bằng SSL. MySQL được cài đặt sẵn một tập lệnh tăng khả năng bảo mật bằng cách xác định cấp độ bảo mật của mật khẩu, xác định mật khẩu cho người dùng gốc, xóa tài khoản ẩn danh và xóa cơ sở dữ liệu test để tránh tình trạng tất cả người dùng đều có thể truy cập được.
Cung cấp đa dạng thư viện nhúng (embedded multi-threaded library), hỗ trợ dung lượng nhỏ (smaller footprint) để sử dụng trong các hệ thống mã nhúng và IoT.
Hỗ trợ các tính năng nhiều người dùng, phù hợp cho các ứng dụng phân tán (distributed applications)
Có khả năng mở rộng theo chiều ngang nhờ hỗ trợ sao lưu bằng cách chia sẻ thông tin giữa hai hoặc nhiều máy chủ
Điểm trừ:
Vì MySQL không hỗ trợ PL/SQL nên không thể sử dụng kết hợp với cơ sở dữ liệu Oracle.
Được thiết kế ưu tiên tốc độ sử dụng và khả năng dễ dùng, MySQL gặp một số hạn chế về một số chức năng. Ví dụ: không hỗ trợ cho FULL JOIN.
MySQL sẽ di chuyển dữ liệu cũ sang một khu vực riêng biệt gọi là phân đoạn khôi phục (rollback segments), các INSERT dữ liệu mới với khối lượng lớn sẽ khiến hiệu suất truy xuất dữ liệu giảm đáng kể so với PostgreSQL. Với các truy xuất phức tạp có thời gian thực hiện kéo dài cũng sẽ xảy ra tình trạng mất kết nối, vì vậy MySQL sẽ phù hợp với các truy vấn đã được đánh chỉ mục (clustered index).
Thiếu tính năng tìm kiếm toàn văn bản và khả năng read-writes dữ liệu đồng thời chậm.
Trong các tình huống cao tải với lượng truy cập lớn, MySQL có thể gặp phải tình trạng tắc nghẽn về hiệu suất.
Cấu hình mặc định không đủ mức độ bảo mật cần thiết cho các ứng dụng quan trọng của doanh nghiệp
PostgreSQL
PostgreSQL là mã nguồn mở (open-source) và không bị kiểm soát bởi bất kỳ doanh nghiệp nào mà được xuất bản trên GitHub và duy trì bởi Nhóm Phát triển Toàn cầu PostgreSQL. PostgreSQL có cả hai lựa chọn hỗ trợ cộng đồng và thương mại. Mặc dù PostgreSQL có thị phần nhỏ hơn so với MySQL, nhưng PostgreSQL đã có một danh sách khách hàng ấn tượng như AWS RedShift, Instagram, ViaSat và Cloudera.

Tổng quan về PostgreSQL - Slide khóa học Data System with SQL
Không giống MySQL, PostgreSQL là một hệ thống quản lý cơ sở dữ liệu có cấu trúc đối tượng (ORDBMS) được thiết kế để hỗ trợ các mô hình dữ liệu phức tạp và đa dạng hơn. PostgreSQL cung cấp một loạt các tính năng dành cho doanh nghiệp, bao gồm khả năng mở rộng, bảo mật và hỗ trợ tự động hóa tốt hơn thông qua giao diện dòng lệnh hoặc truy cập trực tiếp qua web. PostgreSQL hỗ trợ Windows, macOS và một số bản phân phối Linux.
Điểm cộng:
Điểm nổi bật nhất của PostgreSQL chính là khả năng mở rộng theo chiều dọc và tuân thủ các tiêu chuẩn ACID.
Giống MySQL, PostgreSQL sử dụng mô hình cơ sở dữ liệu máy khách/máy chủ (client/server database model) và quy trình máy chủ xử lý các giao tiếp với máy khách, quản lý các tệp và hoạt động cơ sở dữ liệu, được gọi là quy trình postgres.
PostgreSQL là một hệ thống cơ sở dữ liệu quan hệ đối tượng, nguồn mở, tập trung vào khả năng mở rộng và tuân thủ các tiêu chuẩn. Amazon RDS cho PostgreSQL quản lý các tác vụ quản trị cơ sở dữ liệu tiêu tốn nhiều thời gian như cài đặt phần mềm PostgreSQL, quản lý lưu trữ và nâng cấp.
PostgreSQL chia sẻ nhiều ưu điểm tương tự của MySQL - dễ sử dụng, không tốn kém, đáng tin cậy và có một cộng đồng lớn các nhà phát triển. Nó cũng cung cấp một số tính năng bổ sung như hỗ trợ foreign key mà không yêu cầu cấu hình phức tạp.
Do khả năng xử lý song song vượt trội, PostgreSQL đứng đầu (so với MySQL) khi chạy các lệnh SELECT dài như trong các ứng dụng phân tích (analytical applications). PostgreSQL luôn được coi là tốt nhất cho các quy trình phân tích (analytical processes) như lưu trữ dữ liệu vào nhà kho. Một ví dụ điển hình là Timescale DB, có thể cho phép bạn INSERT 1 triệu bản ghi mỗi giây.
PostgreSQL hỗ trợ nhiều loại dữ liệu, chẳng hạn như JSON, XML, H-Store và các loại dữ liệu khác.
Hỗ trợ các thủ tục được lưu trữ (stored procedures), một ngôn ngữ lập trình rất phức tạp được xây dựng dựa trên SQL để tạo điều kiện thuận lợi cho các giao dịch phức tạp và cung cấp sự tuân thủ ACID (Atomicity - Tính nguyên tử, Consistency -Tính nhất quán, Isolation - Cách ly, Durability - Độ bền).
PostgreSQL sử dụng MVCC để duy trì tính nhất quán của dữ liệu trong quá trình truy cập dữ liệu đồng thời. Để có khả năng tương thích ngược hoặc các ứng dụng muốn có công nghệ locks, PostgreSQL cũng cho phép các công nghệ khóa bảng và hàng cung cấp khả năng đồng thời. Ngược lại, MySQL chỉ hỗ trợ MVCC trong các phiên bản InnoDB.
Dễ dàng tích hợp các công cụ của bên thứ ba, ví dụ: ClusterControl cung cấp hỗ trợ ấn tượng trong việc quản lý, giám sát và mở rộng cơ sở dữ liệu nguồn mở SQL và NoSQL. Trong trường hợp bạn định mở rộng quy mô dữ liệu của mình lên khối lượng công việc nặng, hệ thống sao lưu và khôi phục pgBackRest sẽ là một lựa chọn tuyệt vời để bạn lựa chọn.
Điểm trừ:
Truy vấn chạy theo batch, gây cản trở tới tốc độ xử lý dữ liệu.
Khi so sánh với MySQL, PostgreSQL tiêu tốn nhiều năng lượng hơn. Vì PostgreSQL phân nhánh một quy trình dành cho các kết nối máy khách mới nên có thể mất tới 10MB cho mỗi kết nối. Mô hình này có thể chiếm nhiều bộ nhớ khi quá trình kết nối máy khách diễn ra đồng thời khi so sánh với mô hình luồng trên mỗi kết nối của MySQL.
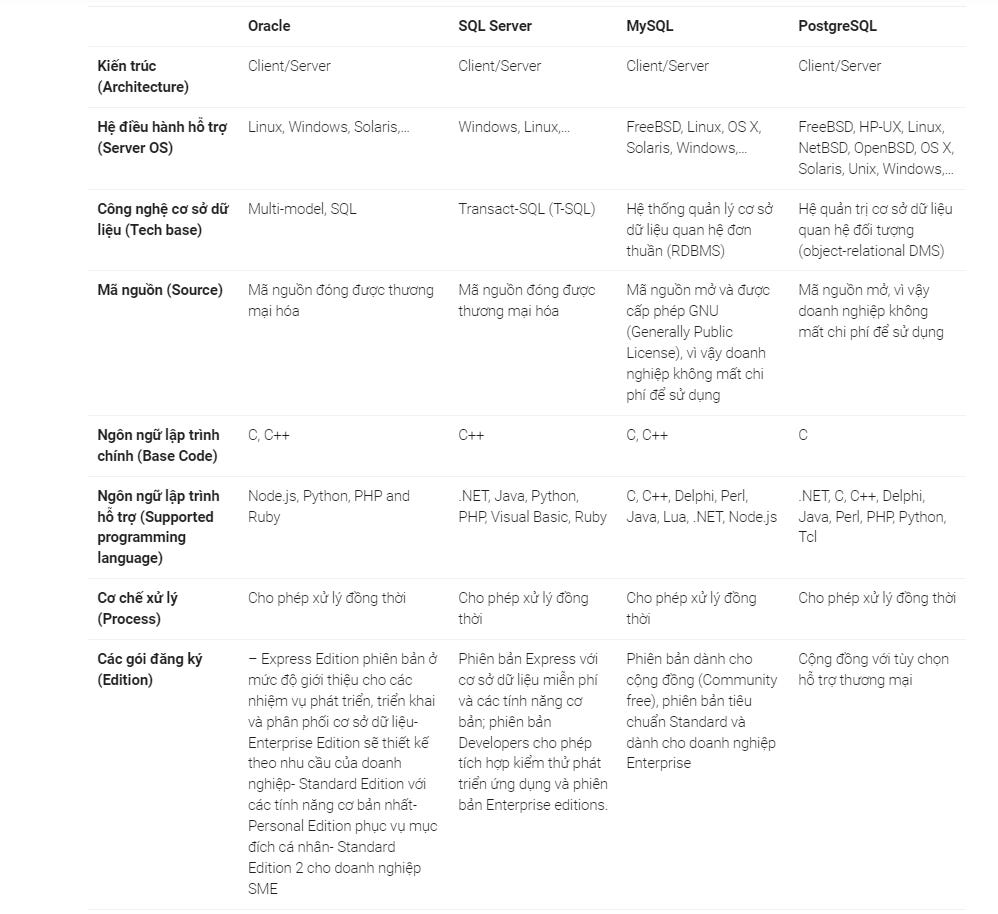
Vậy điểm khác biệt của 4 RDBMS này là gì?



Cần chú ý điều gì khi lựa chọn hệ quản trị cơ sở dữ liệu quan hệ
Lựa chọn RDBMS nào sẽ còn tùy thuộc vào nhu cầu cụ thể của dự án, tính bảo mật, công nghệ của RDBMS, quy mô, yêu cầu về hiệu suất, cân nhắc chi phí và nhiều yếu tố khác.
Hiệu năng: MySQL nổi tiếng với tốc độ xử lý nhanh nhất trong 4 hệ quản trị cơ sở dữ liệu quan hệ, trong khi PostgreSQL được biết đến với khả năng linh hoạt và mở rộng khi doanh nghiệp mở rộng quy mô người dùng và khối lượng dữ liệu, trong khi Microsoft SQL Server vượt trội về hiệu suất xử lý, đặc biệt là trong môi trường doanh nghiệp lớn.
Cộng đồng hỗ trợ: MySQL và PostgreSQL có cộng đồng người dùng lớn vì được phát triển dựa trên mã nguồn mở, trong khi hai mã nguồn đóng đã được thương mại hóa như Microsoft SQL Server và Oracle thì có lượng người dùng nhỏ hơn.
Tính năng: PostgreSQL có thể được coi là có khả năng mở rộng cao nhất, cung cấp nhiều tiện ích mở rộng và tiện ích bổ sung cho nhiều nhu cầu khác nhau. Mặc dù MySQL và Microsoft SQL Server cung cấp nhiều tính năng nhưng PostgreSQL vẫn được đánh giá cao hơn về tính linh ho.
Bạn có thể trả lời một số câu hỏi dưới đây để tìm hiểu về nhu cầu của doanh nghiệp:
Yêu cầu về độ chính xác dữ liệu ở mức độ nào? Việc lưu trữ và độ chính xác của dữ liệu có phụ thuộc vào logic kinh doanh không? Dữ liệu có yêu cầu nghiêm ngặt về độ chính xác không (ví dụ: dữ liệu tài chính và báo cáo của chính phủ)?
Doanh nghiệp có cần khả năng mở rộng (scale) không? Quy mô của dữ liệu được quản lý là gì và mức tăng trưởng dự kiến của dữ liệu là bao nhiêu? Mô hình cơ sở dữ liệu có cần hỗ trợ các bản sao cơ sở dữ liệu được nhân đôi (dưới dạng phiên bản riêng biệt) không? Nếu vậy, nó có thể duy trì tính nhất quán của dữ liệu trong các trường hợp đó không?
Tính đồng thời quan trọng như thế nào? Nhiều người dùng và ứng dụng có cần truy cập dữ liệu đồng thời không? Phần mềm cơ sở dữ liệu có hỗ trợ đồng thời trong khi bảo vệ dữ liệu không?
Nhu cầu về hiệu suất và độ tin cậy ở mức độ nào? Doanh nghiệp có cần một hệ quản trị cơ sở dữ liệu có hiệu suất cao, độ tin cậy cao không? Các yêu cầu đối với hiệu suất phản hồi truy vấn là gì?
Đọc thêm: Có nhiều loại SQL như vậy, bạn nên học loại SQL nào?
4. Hướng dẫn từng bước cài PostgreSQL
Bước 1: Download PostgreSQL
Để cài đặt PostgreSQL trên máy tính, truy cập installer by EDB, và download phiên bản mới nhất tương ứng với hệ điều hành của máy tính.

Bước 2: Bắt đầu cài đặt
Sau khi download, click chuột chọn file đã download và bắt đầu quá trình thiết lập:

Bước 3: Chỉ định thư mục cài đặt
Bạn có thể lựa chọn thư mục nơi PostgreSQL sẽ được cài đặt.

Bước 4: Lựa chọn thành phần sẽ cài đặt
Để sử dụng PostgreSQL, bạn sẽ cần cài đặt PostgreSQL Server, pgAdmin 4, và Command Line Tools, trong đó:
PostgreSQL Server cho phép bạn cài đặt PostgreSQL database server
pgAdmin 4 option cho phép bạn cài đặt PostgreSQL database GUI management tool.
Stack Builder cung cấp một GUI cho phép bạn tải xuống và cài đặt trình điều khiển hoạt động với PostgreSQL.
Command Line Tools cho phép bạn cài đặt công cụ tương tác với máy chủ của cơ sở dữ liệu bằng các câu lệnh như psql, pg_restore,...

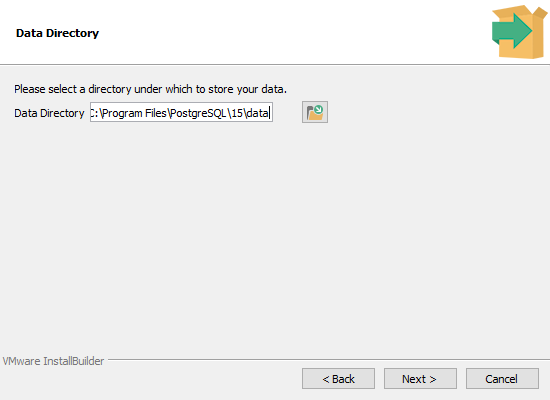
Bước 5: Lựa chọn thư mục lưu trữ
Bạn cũng có thể lựa chọn nơi sẽ lưu trữ dữ liệu của cơ sở dữ liệu, hoặc đồng ý theo mặc định sẽ được lưu trữ tại tệp tin của chương trình:
Bước 6: Cài đặt mật khẩu
Bạn sẽ cần cài đặt mật khẩu để truy cập cơ sở dữ liệu. Bởi đây là cơ sở dữ liệu local (tại môi trường cá nhân) và không có kết nối tới những cơ sở khác, hãy giả sử mật khẩu là 12345678:

Bước 7: Lựa chọn Port (cổng truy cập)
Bạn có thể lựa chọn số port của server (mặc định của PostgreSQL sẽ là 5432), đồng thời hãy đảm bảo rằng không có ứng dụng nào khác sử dụng port này

Bước 8: Lựa chọn ngôn ngữ
Thiết lập ngôn ngữ bằng cách lựa chọn vị trí địa lý của máy chủ cơ sở dữ liệu. Nếu để trống, mặc định của PostgreSQL sẽ sử dụng ngôn ngữ của hệ điều hành:

Bước 9: Check lại lần cuối
Sau khi đảm bảo các thông tin cài đặt đã chính xác, click chọn ‘Next’ để tiếp tục:

Bước 10: Bắt đầu cài đặt
Click 'Next' để bắt đầu cài đặt, quá trình này sẽ mất một vài phút:

Bước 11: Hoàn tất cài đặt
Bạn đã hoàn thiện quá trình cài đặt PostgreSQL trên máy tính cá nhân!

Bước 12: Kiểm tra stack builder prompt
Sau khi quá trình cài đặt kết thúc, sẽ có hộp thoại Stack Builder xuất hiện. Tick không lựa chọn sử dụng Stack Builder và click Finish.

Bước 13: Khởi động PostgreSQL
Vào Start Menu và tìm kiếm pgAdmin 4.

Bước 14: Kiểm tra pgAdmin.
Bạn có thể thấy homepage của pgAdmin

Bước 15: Tìm PostgreSQL 10.
Click chọn Servers và chọn PostgreSQL 10 ở phía bên trái.

Bước 16: Nhập mật khẩu
Nhập mật khẩu đã cài đặt trong quá trình cài đặt và click OK.

Bước 17: Kiểm tra dashboard

Tạm kết
Bởi mỗi RBDMS đều có điểm cộng và điểm trừ khác nhau và có thể được ứng dụng trong nhiều use case khác nhau, một doanh nghiệp có thể sử dụng tới một vài RBDMS để lưu trữ - ví dụ, dữ liệu về giao dịch tài chính được lưu tại MySQL, trong khi dữ liệu của các đơn hàng có thể được lưu tại PostgreSQL,...
Nếu bạn có định hướng trở thành Data Engineer muốn trang bị kiến thức căn bản về các hệ quản trị cơ sở dữ liệu quan hệ và cách xây dựng một hệ thống dữ liệu bài bản, hãy tham khảo khóa học Data System with SQL của TM Data School.
Khóa học sẽ mang đến cho bạn:
Kiến thức bài bản về hệ thống dữ liệu (Data System): Hiểu rõ cấu trúc và từng thành phần của một hệ thống dữ liệu: Data Collector, Data Pipeline, Data Warehouse, Data Mining Tool.
Trọn bộ kiến thức để xây dựng hệ thống dữ liệu từ con số 0: Ứng dụng Data Modelling nhằm xác định cách dữ liệu được tổ chức và liên kết trong nhà kho dữ liệu (Data warehouse) & Biết cách xây dựng các luồng /đường ống dữ liệu (Data pipeline) để kéo dữ liệu từ các nguồn khác nhau về một nơi duy nhất.
Tạo và quản lý dữ liệu trong nhà kho dữ liệu với SQL: Sử dụng các câu lệnh SQL để tạo và quản lý dữ liệu: tạo bảng, chỉnh sửa cấu trúc bảng, tạo ràng buộc (constraints), update bảng, xóa bảng,...
Truy vấn dữ liệu từ cơ bản đến nâng cao với SQL: Nắm vững các câu lệnh truy vấn SQL nhằm hỗ trợ Data Analyst/Data Scientist lấy dữ liệu từ hệ thống phục vụ quá trình phân tích.
Project thực tế thêm vào portfolio: Capstone project xây dựng hệ thống dữ liệu và truy vấn bằng SQL xuyên suốt qua cả khoá học để học viên có thể thêm vào portfolio ứng tuyển công việc.
Ngoài khi tham gia khóa học bạn còn được hướng dẫn bài bản từ các anh chị trainers được đào tạo về Data Science ở nước ngoài.
Tham khảo chi tiết khóa học tại đây!

Bài viết được tổng hợp và biên dịch bởi TM Data School, xin vui lòng không sao chép dưới mọi hình thức!